Every business I’ve ever spoken to has the same problem, even if they describe it differently.
A logistics company drowning in shipping manifests and customs declarations. An insurance firm with thousands of handwritten claims sitting in a queue. A bank whose loan officers still manually key in data from scanned income statements. A healthcare network where critical patient information is buried inside PDFs no system can reliably parse.
The data exists. Intelligence is locked inside it. And for decades, the gap between “we have this document” and “we can use this information” has cost businesses billions in wasted time, human error, and missed opportunity.
That gap is closing fast. And if you’re not paying attention to what’s happening in generative AI for document understanding right now, you’re about to get left behind.
The Scale of the Problem We’re Actually Solving
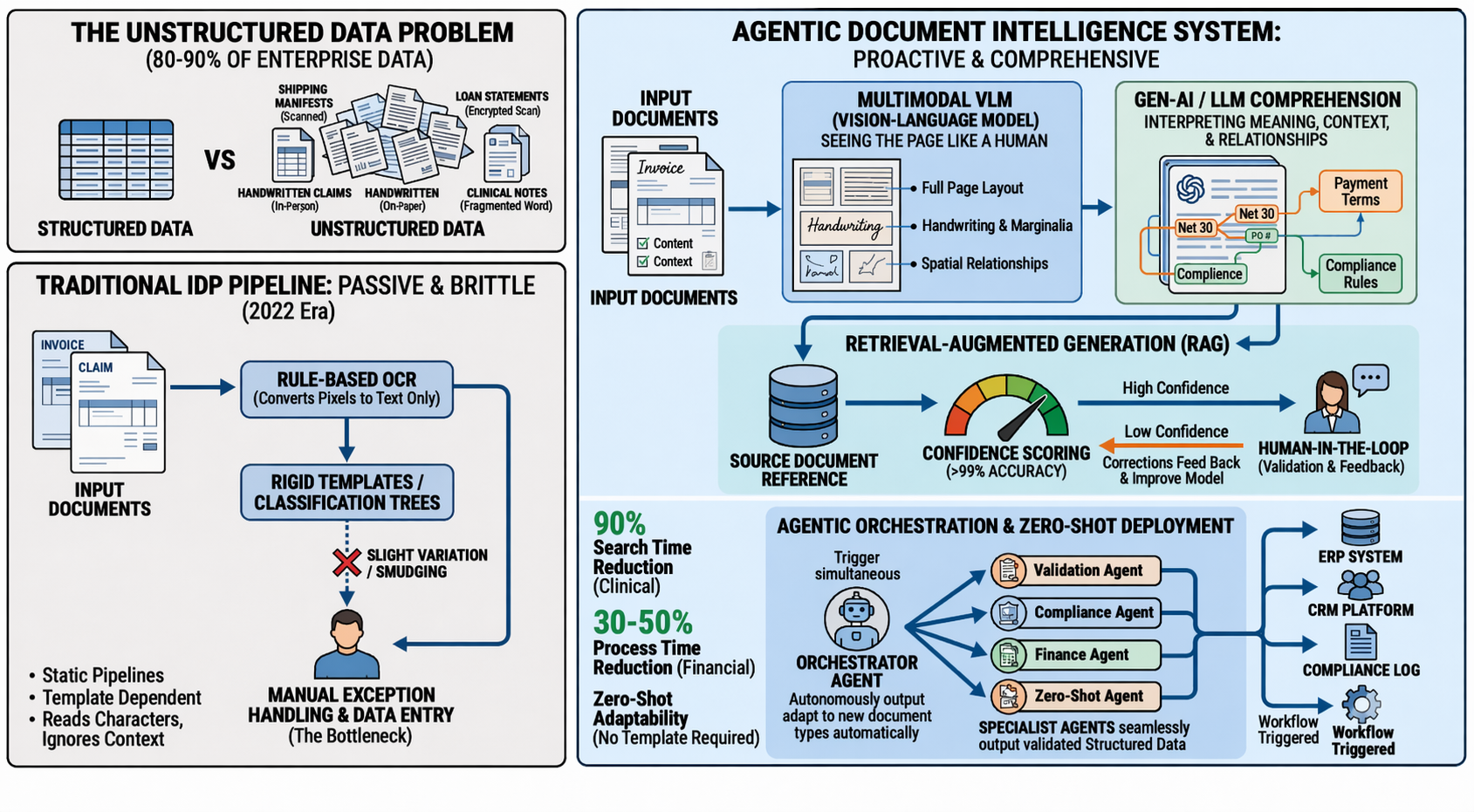
Let’s be clear about what we’re up against. Estimates consistently show that 80 to 90 percent of enterprise data is unstructured locked inside documents, scanned files, emails, images, PDFs, contracts, and forms that traditional software simply cannot read with intelligence. For most businesses, this data has been a liability masquerading as an asset.
The old approaches rule-based OCR, template-driven extraction, rigid classification trees could handle documents that looked exactly like what the system was trained on. Throw a slightly different invoice format at them, or a scanned document with smudging, or a handwritten amendment in the margin, and the whole system breaks. Someone has to step in. A human. Manually.
That was 2022. We are no longer in 2022.
What Has Actually Changed: The Four Pillars of the New Wave
1. LLMs That Understand, Not Just Read
The arrival of large language models capable of genuine document comprehension not just character recognition is the fundamental shift that makes everything else possible. Where traditional OCR converts pixels to characters, modern LLMs interpret meaning, context, relationships, and intent.
This is a profound difference. A traditional system seeing the phrase “net 30” on an invoice doesn’t know what it means. A modern LLM understands it as a payment term, infers it should be linked to the vendor and invoice date, and can flag it against a company’s standard contract terms all without being explicitly programmed to do so.
Generative AI takes intelligent document processing to an entirely new level by not just extracting data but interpreting it, generating summaries, anticipating missing information, proposing corrections, and producing meaningful reports that simulate human-level understanding. This is the leap from “reading” to “comprehending.”
2. Multimodal Vision-Language Models Seeing the Document as a Human Does
One of the most exciting developments in the past 12 to 18 months has been the maturation of vision-language models (VLMs) into production-ready tools. These are AI systems that can simultaneously process the visual layout of a document and its textual content treating a page the way a human actually sees it, not as raw text.
This matters enormously in practice. A scanned insurance claim isn’t just text. It’s a structured form with checkboxes, handwritten fields, stamps, tables, and sometimes sticky notes or marginalia. A traditional OCR pipeline strips out the layout and loses critical context. A modern VLM reads the whole page understanding that a number in the top-right corner is probably a reference code, that a circled figure is flagged for attention, that the table on page three is the financial summary, not just a grid of numbers.
What were previously impressive proof-of-concept demonstrations became production tools you could actually deploy in 2025, as vision encoders, large context windows, and reasoning capabilities finally converged. Multimodal RAG systems which embed images alongside text chunks have demonstrated retrieval accuracy improvements of 25 to 40 percent over text-only approaches. That’s not incremental. That’s a category shift.
3. Agentic AI From Extraction to Action
This is where things get genuinely transformative, and where I spend most of my time thinking about the next two to three years.
Traditional intelligent document processing, even with AI, is still largely passive. You feed it a document; it returns structured data. A human then takes that data and does something with it. The bottleneck shifts from “reading the document” to “acting on what was read.”
Agentic AI breaks that bottleneck entirely. An AI agent doesn’t just extract data from a document it autonomously classifies the document, validates the extracted fields against business rules, cross-references information from other systems, flags anomalies, routes exceptions to the right human, and triggers downstream actions in connected platforms. All of this happens in a continuous, event-driven workflow with no manual prompting at each step.
The new architectural paradigm looks like this: when a document enters the system, an orchestrator agent triggers an extraction event. Specialist agents handle different aspects one validates financial figures, another cross-references vendor databases, another checks compliance rules. Validated data flows directly into the ERP, the CRM, the compliance log. Exceptions surface to humans with full context already assembled. The human isn’t a processor anymore. They’re an approver.
We are seeing enterprises implement this architecture and report 30 to 50 percent reductions in process time. One case I find particularly striking: an agentic system deployed for clinical document processing reduced the time medical staff spent searching through fragmented data sources by 90 percent. That’s not a productivity gain. That’s a clinical capability gain.
4. Zero-Shot and Few-Shot Learning No More Template Dependency
The oldest frustration in document automation has been template dependency. Build a system to extract data from your supplier’s invoice? Great until that supplier changes their invoice format and the whole thing breaks. Scale that problem across hundreds of document types from thousands of sources and you understand why enterprise document automation has historically been so fragile and expensive to maintain.
Modern GenAI systems have shattered this constraint. Zero-shot learning means a model can handle a document type it has never seen before, using contextual reasoning rather than pattern-matching against a known template. Few-shot learning means that with as few as 10 to 50 labeled examples, you can fine-tune a foundation model to achieve high accuracy on a new, specialized document type.
This is the difference between a system that needs to be reprogrammed every time a supplier changes their letterhead and a system that reads the new format, figures out what everything means, and keeps working. The operational implications for businesses dealing with diverse, ever-changing document landscapes are enormous.
The Industries Where This Is Hitting Hardest
Every industry that generates significant document volume is being disrupted, but a few are experiencing transformation at a pace I don’t think people fully appreciate yet.
Financial Services is perhaps the most obvious. Loan origination alone processing income statements, ID documents, bank statements, credit reports is a multi-trillion dollar process globally that has relied on human data entry for decades. AI agents can now ingest all of these document types simultaneously, cross-reference them, flag inconsistencies, and generate a risk-assessed summary for the underwriter in seconds. Beyond lending, contract review, regulatory compliance documentation, and financial reporting are all undergoing similar shifts.
Healthcare is where the human stakes are highest. Clinical documentation, patient records, insurance pre-authorizations, medical coding these are areas where errors have life-or-death consequences and where the volume of paperwork has historically consumed time that clinicians should be spending on patients. Automated classification of grievances versus appeals, intelligent extraction from medical records, and multi-document synthesis for care coordination are no longer future-state scenarios.
Legal and Compliance work is fundamentally document-intensive, and the ability to reason across large collections of contracts, identify non-standard clauses, flag compliance gaps, and generate comparative summaries is arriving at exactly the moment when regulatory complexity is increasing globally. Logistics and Supply Chain deal with a document zoo purchase orders, customs declarations, bills of lading, certificates of origin, invoices often in multiple languages, from dozens of jurisdictions, under time pressure. AI systems that can process 35,000 to 45,000 daily documents with 85 percent or better classification accuracy aren’t hypothetical. They’re deployed today.
The Architecture Shift That Matters Most: RAG Meets Document Intelligence
One conversation I have constantly is about hallucination the tendency of AI systems to generate plausible-sounding but incorrect information. In document processing, this is a real concern. You cannot have a system confidently extracting a wrong number from a financial document.
The architectural answer is Retrieval-Augmented Generation (RAG) specifically designed for document contexts. Rather than asking the LLM to rely purely on what it learned during training, a RAG-enabled document system grounds every extraction and inference in the actual source document. The model generates its outputs with the document as a live reference, not from memory.
Combined with confidence scoring where the system assigns a probability to each extracted field and routes low-confidence extractions to human review this creates a genuinely trustworthy pipeline. Human-in-the-loop validation isn’t a fallback for when the AI fails; it’s a designed quality control point that keeps getting smarter as human corrections feed back into the model.
The best systems today achieve greater than 99 percent accuracy on high-volume document types. That’s not a marketing number it’s achievable when you combine strong foundation models with RAG grounding, confidence scoring, and structured human feedback loops.
What’s Coming Next: The Frontier We’re Building Toward
Predictive Document Intelligence
The next evolution beyond extraction and classification is prediction. Future systems won’t just read what’s in a document they’ll use historical document patterns to detect anomalies before they become problems, forecast workflow bottlenecks, identify potential fraud signals, and flag compliance risks proactively. A system that tells you “this invoice has characteristics that historically correlate with payment disputes” before anyone has disputed anything is a fundamentally different tool than one that simply digitizes the invoice.
Multi-Agent Document Orchestration
The multi-agent paradigm where multiple specialized AI agents collaborate on a complex task, passing context between them and coordinating decisions in real time is still early in its enterprise adoption but developing rapidly. Gartner projects that by the end of 2026, approximately 40 percent of enterprise applications will include task-specific AI agents, up from less than 5 percent in 2025. For document-intensive industries, this means purpose-built agent ecosystems: a classification agent, an extraction agent, a validation agent, a compliance agent, all working in concert on a single document workflow.
On-Premise and Private Deployment of Powerful Models
A genuine barrier to adoption for many regulated industries has been data sovereignty. The most capable AI models have historically lived behind cloud APIs, which creates real concerns for healthcare organizations, financial institutions, and government agencies that cannot send sensitive documents to external services. The performance gap between open-source and proprietary models has narrowed from roughly 8 percent to under 2 percent on key benchmarks over the past year. This convergence means organizations with strict data residency requirements can increasingly deploy powerful models on their own infrastructure without meaningful accuracy penalties.
Conversational Interfaces on Extracted Data
One of the capabilities I find most compelling for business users is natural language interaction with extracted document data. Instead of receiving a structured data export and figuring out what to do with it, users can ask questions: “Summarize all invoices from this vendor for Q1.” “Which contracts expire in the next 90 days and contain automatic renewal clauses?” “Show me all transactions above a threshold where the invoice total doesn’t match the PO.” This turns document intelligence from a backend process into a business intelligence tool that anyone in the organization can use.
What This Means If You’re an Enterprise Evaluating This Technology
One thing we’ve learned from years of building these systems first with traditional OCR and legacy tooling, now with GenAI is that the technology itself is rarely the hard part. The hard part is everything around it.
Generic platforms and off-the-shelf AI tools tend to work well in demos and struggle in production. Every enterprise document problem comes bundled with edge cases, legacy system integrations, regulatory constraints, and workflow quirks that no pre-packaged solution fully anticipates. Basic OCR and extraction are increasingly commoditised the underlying models are capable and accessible. What actually determines success is domain-specific accuracy on your document types, human-in-the-loop workflows that improve over time, deep integration with the systems where your extracted data needs to live, and governance that gives your compliance team confidence.
The question is no longer “can AI read this document?” It’s “what needs to happen after the document is read, and does this solution actually handle that?” That’s where the real evaluation should happen and where custom engineering, built around how your business actually operates, consistently outperforms generic tooling.
A Final Thought
We’ve been building custom document processing software for enterprises across both eras traditional OCR and rules-based pipelines, and now modern LLMs and GenAI. The problems clients bring us haven’t changed: too many documents, too much manual effort, too many errors. What has changed is what we can actually build for them. The ceiling on what’s possible has risen dramatically, and the gap between businesses that move on this and those that don’t is widening every quarter.
If you’ve tried generic platforms and found them wanting, or you’re sitting on a brittle legacy system that can’t keep up that’s exactly the kind of problem we exist to solve. Not with an off-the-shelf product, but with engineering that’s built around how your business actually works.